
GraphQL 은 페이스북에 의하여 REST API 의 문제를 해결하기 위해 만들어졌습니다.
기본적으로 REST API 여러개의 URL을 활용하여 작동합니다. 모든 URL 은 각각 고유하고, 각기 다른 데이터를 제공합니다.
하지만, 이러한 REST API 는 2가지 큰 문제점을 가지고 있습니다.
Problems
1. Over Fetching
클라이언트가 필요한 것보다 더 많은 데이터를 가져오게 되는 경우를 Over Fetching 이라고 볼 수 있습니다. 예를 들어, 영화 목록에서 제목만 필요하지만, 영화 목록을 가져오는 API 는 제목, 내용, 사진 url 등 더 많은 정보를 돌려주게 구현되어있는 경우가 있을 수 있죠. 만약 조금이라도 다른 응답의 데이터를 가지고 오고 싶다면, 새로운 엔드포인트 API 구현이 필요해집니다.
query parameter 를 활용하면 되지 않을까? 하는 의문이 들 수 있습니다. 저도 그랬고요. /list?field=title 과 같은 식으로 요청하면 title 만 돌려주게 구현할 수 있을 것입니다. 다만, 이는 표준화된 방식이 아니죠. 그리고 더 복잡한 데이터 요청은 query parameter 만으로 요청하는 것이 오히려 어려울 수 있습니다.
GraphQL 은 이러한 문제를 해결해줍니다. GraphQL 의 QL 이 Query Language 인 것 답게, 이는 클라이언트가 정확하게 필요한 데이터만 요청할 수 있게 해줍니다.
2. Under Fetching
Under Fetching 은 Over Fetching 과 반대되는 말로, 필요한 만큼의 데이터를 한번에 가져오지 못한다는 문제점을 의미합니다. 예를들어, 클라이언트에서 게시글을 클릭했을 때 포함되어야 하는 정보는 다양하게 존재합니다. 게시글 그 자체에 대한 데이터, 게시글 작성자에 대한 데이터, 게시글 댓글에 대한 데이터가 포함될 수 있죠. 만약 이를 각각의 엔드포인트로 구성하였다면, 클라이언트에서는 다음과 같이 3가지 GET 요청을 보내야할 것입니다.
/posts/{id} to get the post.
/authors/{id} to get the author of the post.
/posts/{id}/comments to get the comments on the post.GraphQL 에선 이를 간단하게 한번의 요청만으로 해결해 줍니다.
query {
post(id: "1") {
title
content
author {
name
bio
}
comments {
content
date
}
}
}REST API 에서도 물론 한번의 요청으로 이를 해결할 수는 있습니다. /post/{id}/detail 과 같은 API 를 추가로 구현하면 되겠죠.
하지만, 서비스가 커지며 데이터 모델이 점점 변경되고, 비슷하지만 다른 응답이 요구되는 다양한 상황이 추가될 수 있습니다. 이 때마다 새로운 API 를 작성하는 것은 매우 비효율 적일 것입니다. 데이터 모델은 변화가 없지만, 단순히 다른 형태의 응답이 요구되는 경우에도 클라이언트와 서버 작업이 모두 이루어 져야 할 것입니다.
그에 비해 GraphQL 을 활용할 경우에는, 데이터 모델에 변화가 없는 상황에선, 클라이언트 개발자가 단순히 필요한 정보의 새 쿼리를 만들면 끝입니다.
물론 GraphQL 을 잘 활용하기 위해선, 서버 개발자가 보다 정확한 타입의 스키마를 정의하고, 중첩된 쿼리를 해결하고, 쿼리 최적화와 같은 작업을 처리해야 하기 때문에 REST API 에 비하여 사전 작업이 더 필요할 수는 있습니다. 하지만 사전 작업이 모두 완료되면, GraphQL은 클라이언트에게 매우 유연하고 효율적인 API를 제공할 수 있습니다.
GraphQL 은 어떻게 동작하나요?
실질적으로 GraphQL 의 구현은 REST 와 마찬가지로 HTTP 요청과 응답을 활용하며, 데이터는 json 포맷으로 이루어져 있습니다. 메서드는 일반적으로 POST 가 사용됩니다. GraphQL 쿼리 자체가 body 에 포함되기 때문이겠죠.
응답 코드는 서버 자체 에러나, GraphQL 을 파싱할 수 없는 경우 등 특별한 상황을 제외하면, 항상 200 이 리턴됩니다. 응답 데이터에서 에러 여부, 에러 메세지를 돌려보내는 것이죠.
GrpahQL 의 결함은 무엇이 있을까요?
비교적 무거운 툴과 함께 사용해야 합니다.
REST 의 경우 특별한 라이브러리 없이도 다른 누군가의 API 를 호출할 수 있습니다. 단순히 curl 을 통해서도 가능하죠. 이에 비하여 GraphQL 은 클라이언트, 서버 모두 꽤 무거운 툴이 필요합니다. 이는 꽤 큰 금액의 비용을 발생시킬 수 있죠. 만약 단순히 CRUD 를 활용하는 서비스를 개발하는 것이라면, 이는 금액적으로 많이 비효율적일 것입니다.
캐싱 기능이 비교적 떨어집니다.
REST 는 GET 메서드를 자주 활용하며 데이터를 요청하는데, 이 GET 메서드는 잘 정의된 캐싱 기능들이 존재합니다. 다양한 브라우저, CDNs, 프락시, 웹서버에서 이를 활용하죠. 그에 비해 GraphQL 은 기본적으로 POST 메소드를 활용합니다. 이는 HTTP caching 을 최대로 활용할 수 없게 만들죠.
잘만 다룬다면, GraphQL 도 HTTP caching 을 잘 활용할 수 있습니다. 다만, 상세한 내용은 복잡하기 때문에, 결국 HTTP 캐싱을 잘 활용하기 위해선 추가적인 작업이 필요하고, 그 작업이 사소하진 않을 것이라는 점을 이해하고 넘어가는게 좋을 것 같습니다.
클라이언트가 원하는 데이터를 요청할 수 있다는 점이 단점이 될 수 있습니다.
클라이언트에 새로운 기능이 추가되며, 서버에서 예상치 못한 데이터를 요청하는 경우가 생길 수 있습니다. 이러한 요청이 크리티컬한 테이블 스캔을 발생시킬 수 있고, 이는 데이터베이스 다운으로 이어질 수 있습니다.
완화하는 방법은 있지만, 이는 GrpahQL 구현에 복잡성을 증가시킵니다.
위 3가지 결함에 대한 보호 조치 비용은 GraphQL 사용 여부를 선택하는데 중요하게 고려해야할 요소입니다.
GraphQL 의 특징
GraphQL 단순하게 표현하면 API Layer 에서 사용 가능한 Query Language 라고 할 수 있으며, 크게 3가지 특징을 추려보면:
- 필요한 것만 요청하고 받아오기
- 단일 요청으로 많은 데이터를 가져오기
- 가능한 케이스를 타입 시스템으로 표현하기
정도가 존재합니다. 여기서 1, 2번은 쉽게 이해할 수 있습니다. 결국 둘 다 payload 를 최적화 하는 것이 목적인 것이죠. 하지만, GraphQL의 진정한 강점은 3번, 클라이언트 사이드에서 타입 시스템을 구축할 수 있다는 점인 것 같습니다.
아무래도, 실제 서비스에서 어떻게 사용되는지 볼 수 있으면 가장 좋겠죠. NAVER DEVIEW 2023에서 권기범, 오제관님께서 발표한 "GrpahQL 잘 쓰고 계신가요?" 를 꼭 한번 보시길 추천 드립니다. 저는 그 중 중요하다고 생각하는 몇가지 요소를 간단하게 요약해 보겠습니다.
타입 시스템
네이버의 MY플레이스 서비스는 여러 화면에서 내부 DB 는 물론, 다양한 다른 팀에 API 를 사용한다고 합니다. 이를 각각의 컴포넌트에서 직접 연결하여 사용할 수 있겠지만, 클라이언트 개발자 입장에서는 상당히 번거롭고, 신경쓸게 많아질 수 있겠죠. 이 때문에 MY플레이스 서비스 팀에선 중간단계에 GraphQL BFF 를 두었습니다.
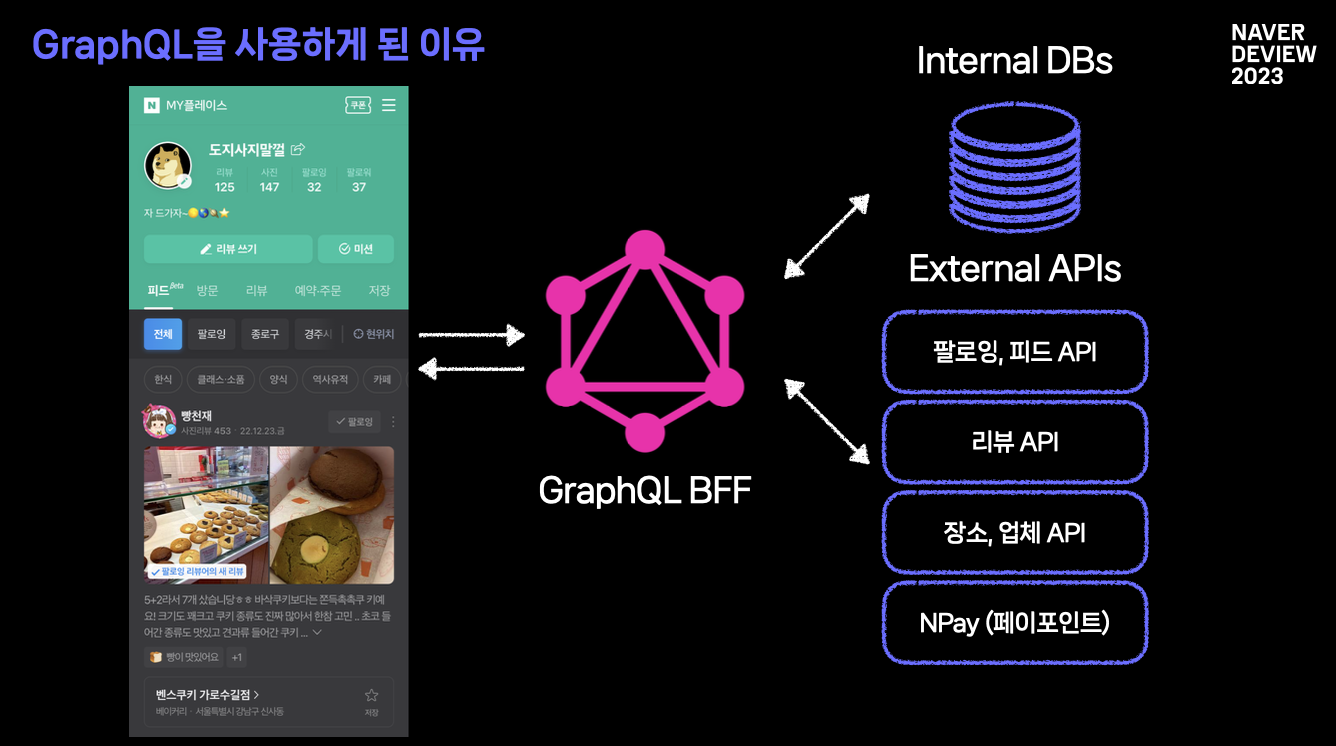
여기서 BFF 란 Back-End For Front-End 의 약자로, 클라이언트 개발자를 위한 일종의 게이트웨이라고 볼 수 있습니다. 이는 여러 자원의 출처를 하나의 타입시스템으로 관리할 수 있게 해줍니다. 이를 통해 클라이언트는 오직 한가지 엔드포인트만 활용하며 GrpahQL 을 통해 원하는 데이터를 주고 받을 수 있는 것이죠.
즉, 출처가 다른 데이터들의 통합 타입 시스템 이 구축됩니다. 이제 클라이언트 개발자는 여러 내부/외부 API 를 신경쓸 필요 없이, BFF 에서 제공되는 타입들을 활용화며, 화면 중심으로 스키마를 작성해 나갈 수 있습니다. 이를 통해 클라이언트 개발자의 DX 가 상당히 좋아집니다.
Normalization
다음으로 한가지, 일반적인 REST API fetch 라이브러리에서는 활용이 불가능한 중요한 기능이 GraphQL 구현 라이브러리에는 존재합니다. 그것은 바로 Normalization 이죠.
이게 무엇인지 알아보기 전에, 기존에 REST API 를 사용할 때의 상태 변화에 따른 UI 업데이트 문제를 살펴보겠습니다.
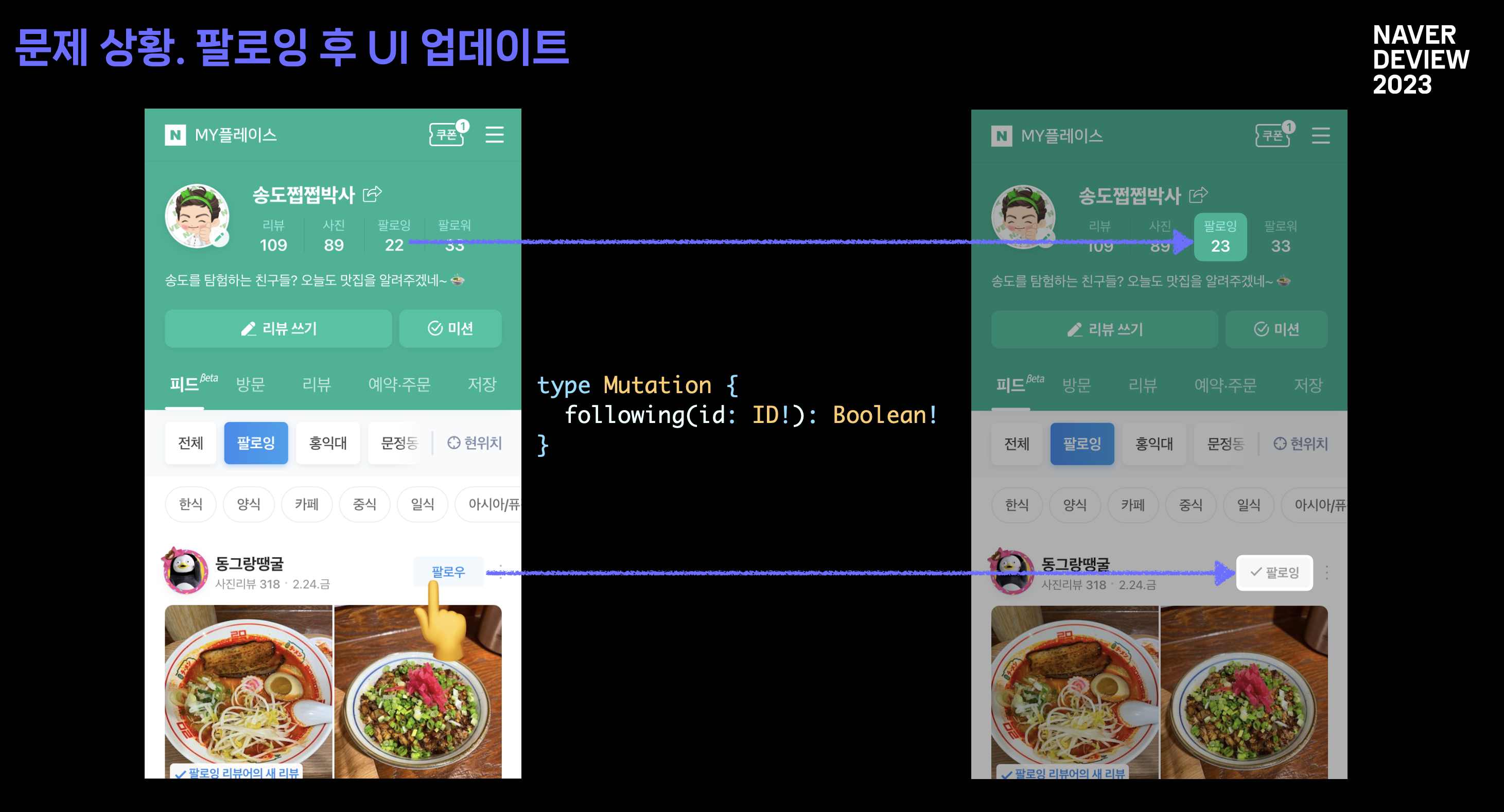
유저가 하단 피드에 팔로잉 버튼을 클릭하였을 때, 크게 2가지 상태가 업데이트 되어야 합니다. 팔로우 버튼이 팔로잉으로 변해야 하고, 상단 프로필에 팔로잉 숫자 또한 업데이트 되어야 합니다. (물론, 실제 서버 구현에 따라 팔로잉 수가 바로 변하지 않을 수는 있지만, 이 발표에서는 유저가 팔로잉시 팔로우 수도 바로 변한다고 가정한 것 같습니다)
기존에 클라이언트 개발자라면 이를 어떤식으로 구현할까요? 먼저, 상태 관리 프레임워크를 통해 이를 직접 관리하는 방법입니다.

집중력 총동원이 필요하겠죠. 구조가 복잡해질수록 이를 직접 찾아서 등록하는 것이 번거로울 것입니다.
두번째 방법은, 무지성 refetch 가 있을 것 같네요.
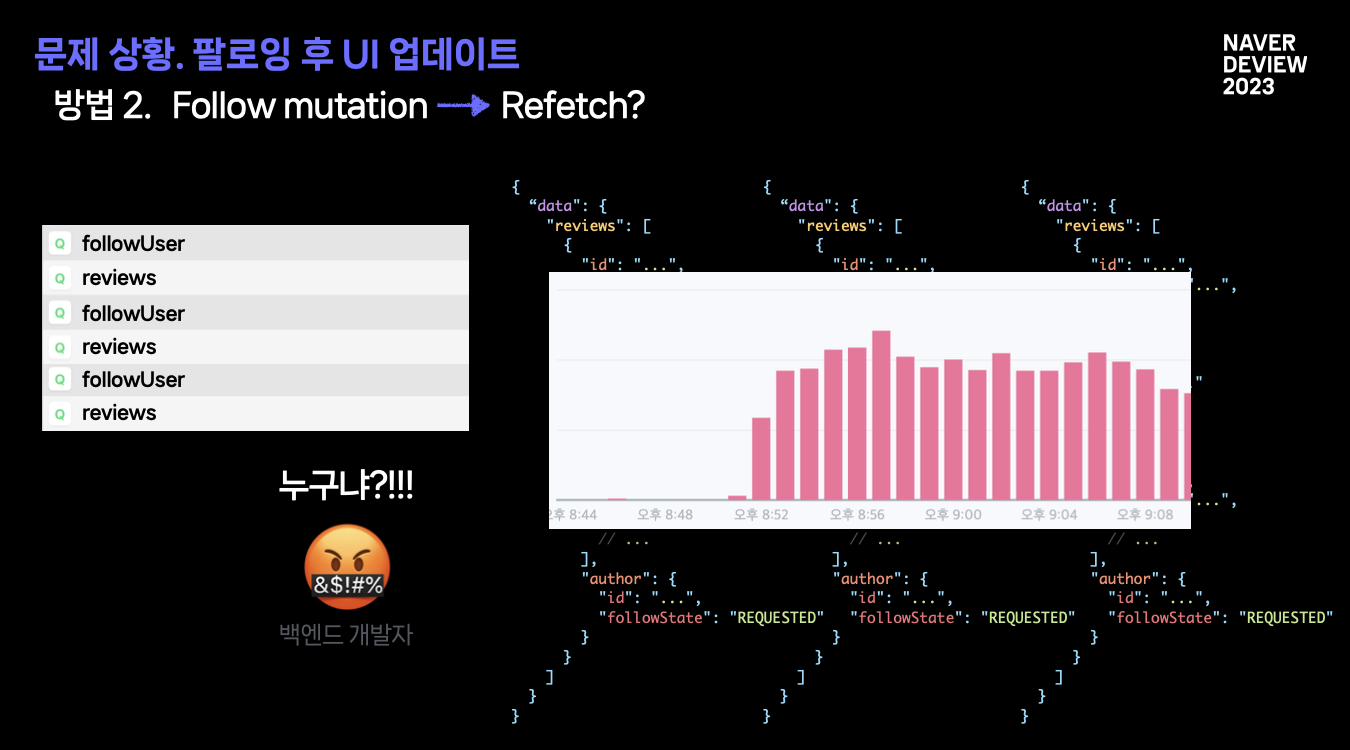
서버 개발자의 원성을 살 수 있을 것 같아요. 사실 단순히 원성의 문제가 아니라, 리소스 비용을 증가시키는 것이기 때문에 더욱 주의해야할 것 같습니다.
이러한 상황에서 GraphQL 의 Normalization 이 빛을 발합니다. GraphQL 은 일반적인 Rest API 방식과 다르게, 서버로 부터 응답받을 모든 데이터 스키마 타입을 미리 알고 있기 때문에, 1. 서로 다른 컴포넌트에서 같은 상태를 참조할 수 있고, 2. 중복된 데이터가 존재하지 않도록 Normalization 이 가능해 집니다.
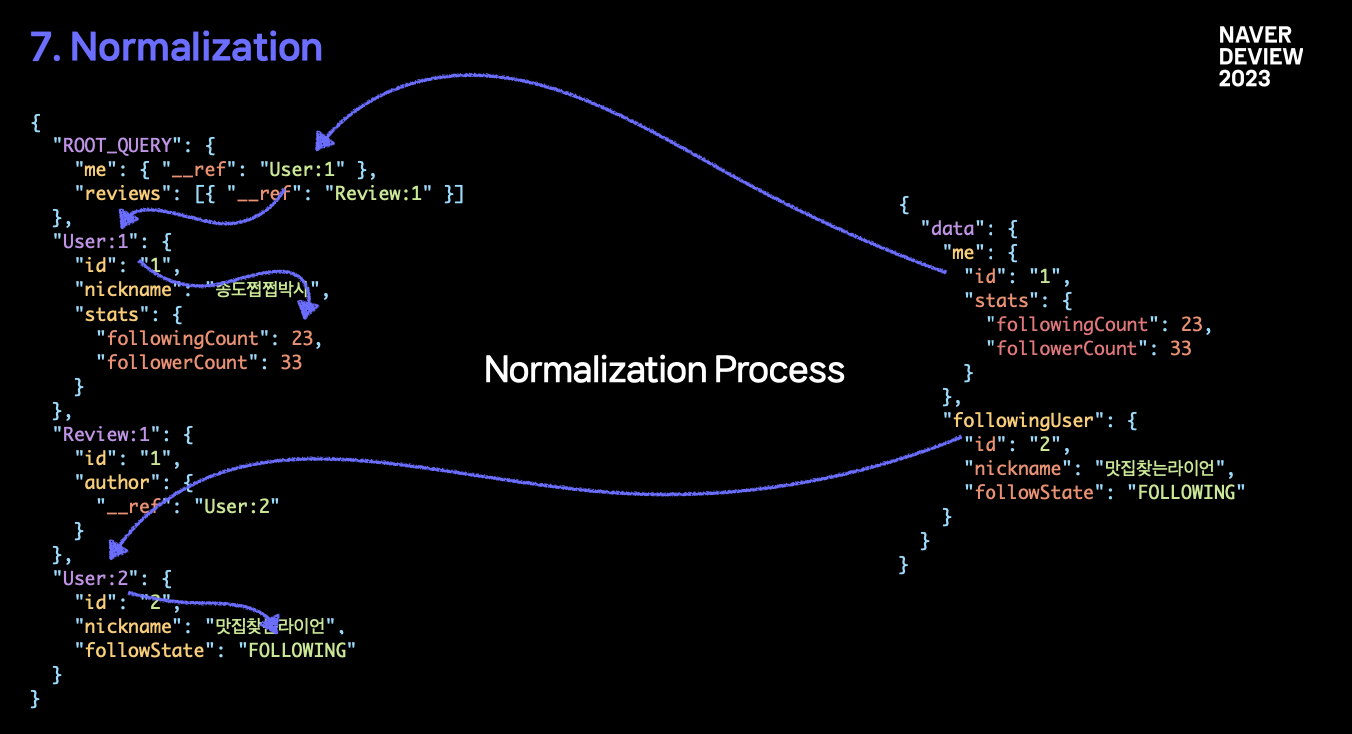
먼저, 우측의 json 형식의 data 는 일반적인 GraphQL 요청에 따른 데이터 응답입니다. 클라이언트가 화면을 업데이트 하는데 필요한 follwingCount, followState 값이 들어있죠.
좌측은 Normalized Cache 로, GraphQL 라이브러리를 통해 관리됩니다. 응답이 도착하면, GrpahQL 라이브러리는 Normalize Process 에 따라 필요한 필드에 값을 업데이트 합니다.
이게 끝입니다.
클라이언트에서는 화면 UI 업데이트를 위해 Global State Manager 를 사용할 필요도, Refetch 할 필요도 없어집니다.

마찬가지로, 클라이언트 개발자의 DX 가 상당히 좋아지겠죠?
Fragment
다음으로, GraphQL 의 특징 중 하나인 Fragment 에 대하여 이야기해 보겠습니다. 이를 잘 이해하려면, 기존에 어떤 문제가 존재하는지 살펴보는게 빠르겠죠.

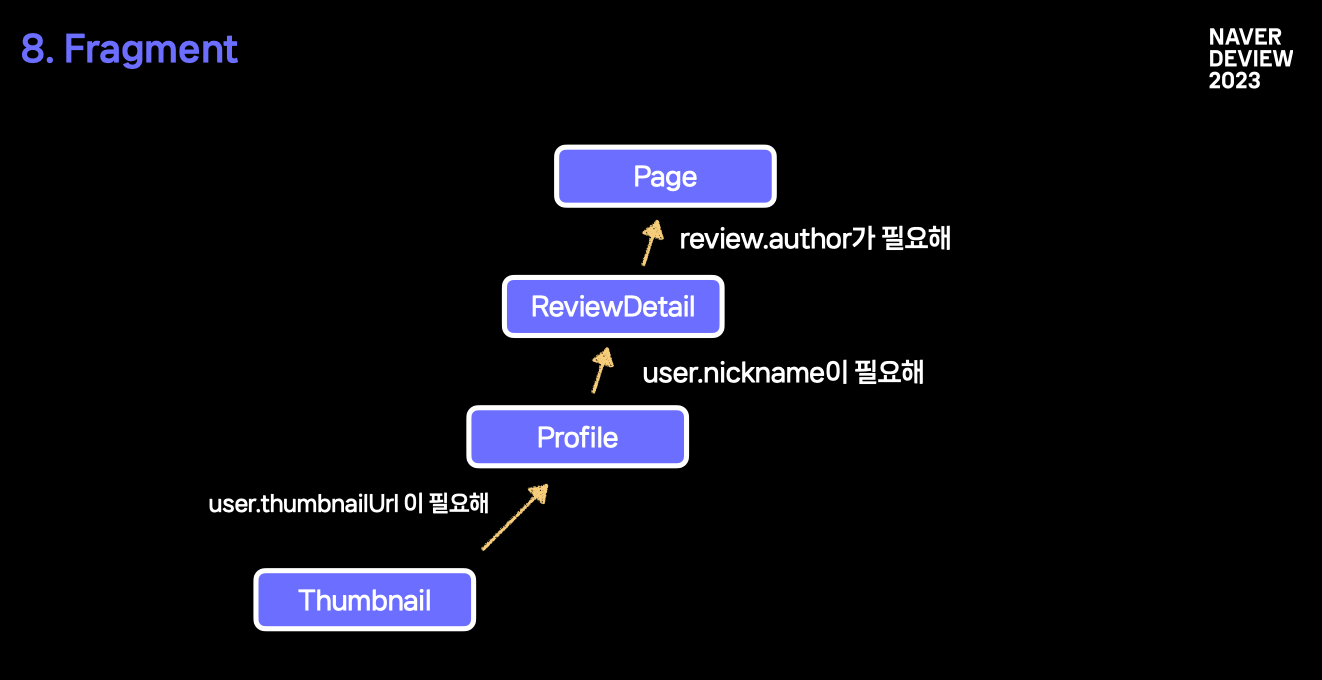
문제가 보이시나요?
문제는 쿼리를 보내는 곳과 쓰는 곳 사이의 거리가 멀다는 것이죠. 최상위 컴포넌트에서 쿼리를 보내고, 값이 필요한 컴포넌트까지 이를 내려주어야 하는데, 거리가 점점 멀어집니다.
하위 컴포넌트에 새로운 데이터 의존성이 생긴다면, 상위 컴포넌트까지 직접 따라가서 이를 추가해 주어야겠죠. Component tree 가 더 복잡하고 호출처가 다양해진다면, 이와 관련한 데이터 의존성의 변경이 필요한 경우 많이 번거로워 질 것입니다.
두번째 문제는, 최상위 Query 에서 필드별 사용 유무 판단이 어렵다는 점입니다. 응답으로 받은 데이터 하나를 하위 컴포넌트에서 사용하는지 여부를 알고 싶다면, 모든 컴포넌트를 뒤져봐야겠죠. 결국 이는 변경을 어렵게 만듭니다.
만약, Component 가 자신이 필요한 데이터 의존성을 선언만 하고, Bottom-Up 방식으로 최상위 Query 에게 전달된다면 이 문제가 해결될 수 있지 않을까요?
이를 가능하게 해주는 것이 바로 Fragment 입니다.
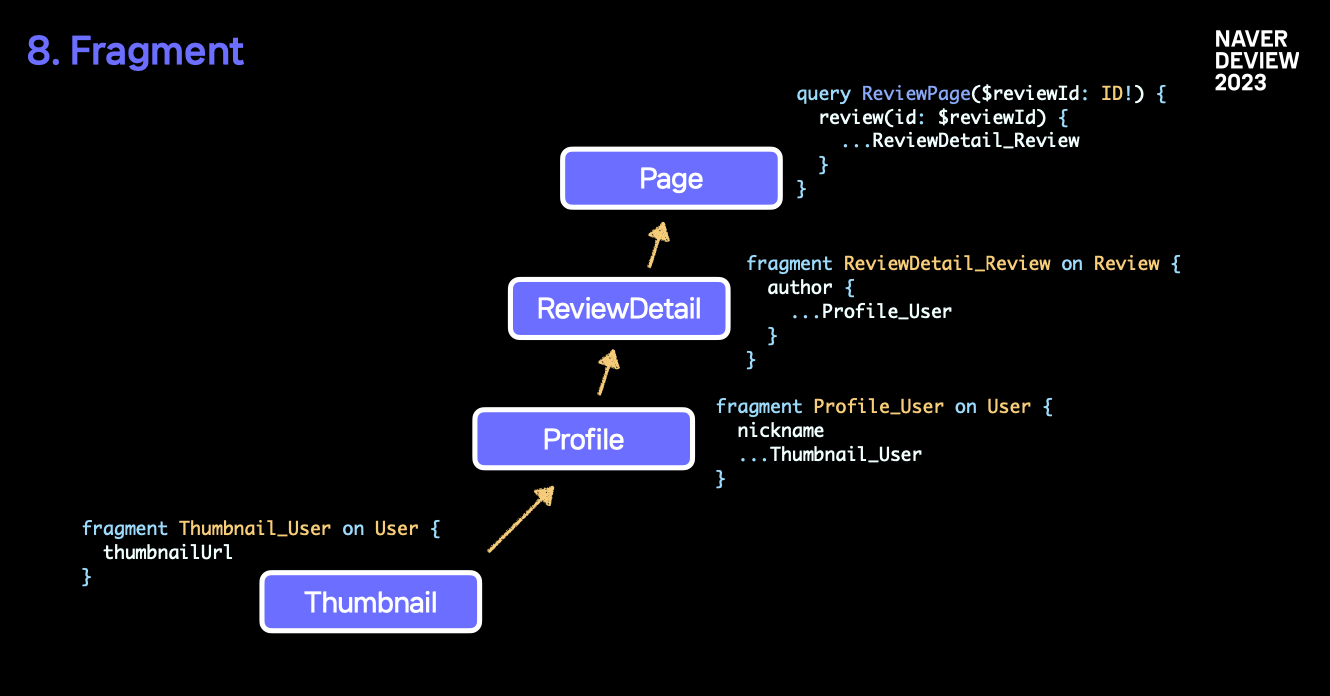
각 컴포넌트는 본인이 필요한 데이터를 Fragment 로 작성합니다. 이는 최상위 Query 로 전달되어 한번에 요청으로 전달되고, 각각의 필요한 응답은 각 Fragment 를 선언한 컴포넌트에게 저절로 떨어지게 되죠.
만약 새로운 데이터 의존성이 생긴다면?
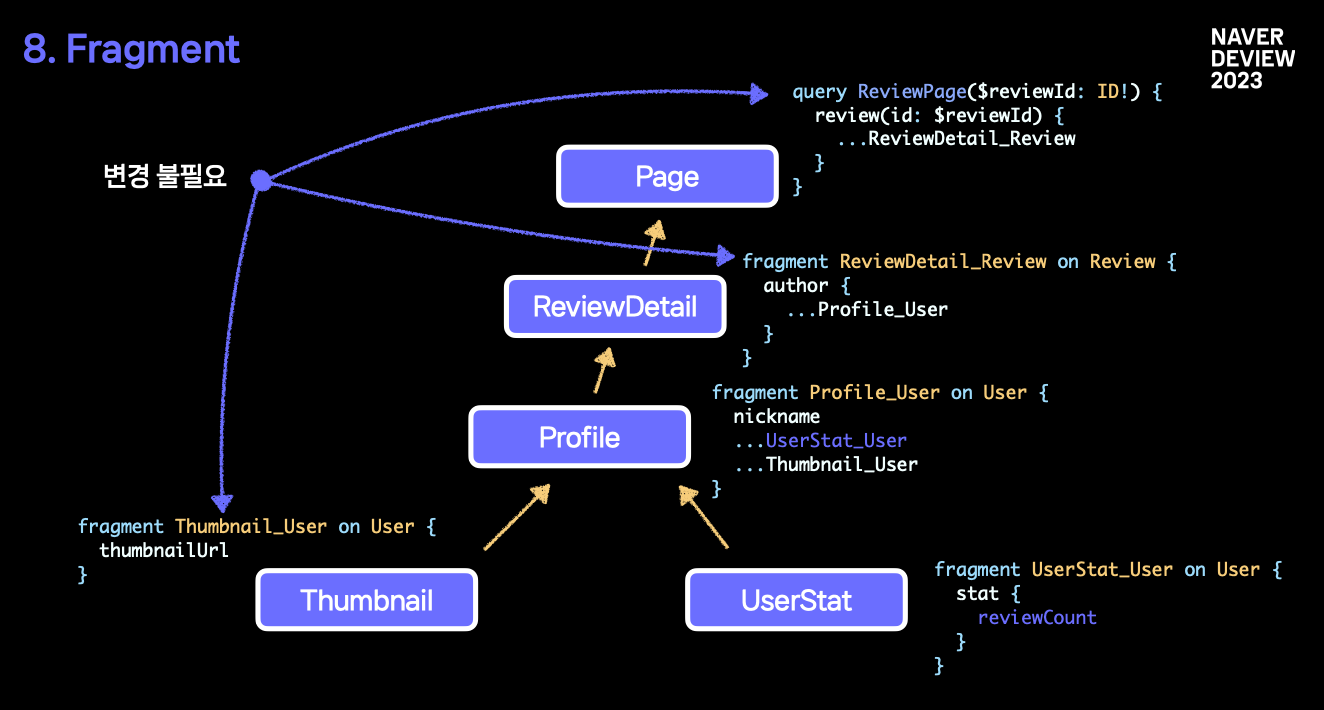
다음과 같이 간단하게 해결됩니다.
다시한번, 클라이언트 개발자의 DX 가 증가하겠죠? ㅎ

발표는 DX 의 증가는 UX 의 증가로 이루어 질 것이라고 말씀해 주시면서 마무리 됩니다. (공감합니다)
이 외에도 여러가지 중요한 핵심 특징이 많으니 궁금하신 분들은 하단 참고에 url 을 따라 DEVIEW 를 직접 시청하시는 것을 권장드립니다.
정리
사실 GraphQL 을 제대로 공부해보기 전까지는, GraphQL 이 만능인 줄로 알고 있었습니다. 하지만, 분명히 문제점도 존재하고 trade-off 이기 때문에 이를 비지니스 레벨에서 활용하려면 많은 고민이 필요하겠죠.
다만, 클라이언트 어플리케이션을 직접 구현해 본 입장에서, GraphQL 이 가져다 주는 변화는 정말로 좋은 DX 를 보장해 줄 것이라는 점은 확실한 것 같습니다.
새로운 것을 시도하는 것은 좋은 개발자로 발전하기 위한 소양이라고 생각합니다. 다음에 클라이언트 어플리케이션을 개발할 기회가 있다면, 꼭 한번 GraphQL 을 사용해 보고 싶다는 생각이 드는 것 같습니다.
참고
https://www.youtube.com/watch?v=N-81mS2vldI
https://www.youtube.com/watch?v=9G2vT4C4sAY
https://www.youtube.com/watch?v=yWzKJPw_VzM
- ChatGPT-4
GraphQL 은 페이스북에 의하여 REST API 의 문제를 해결하기 위해 만들어졌습니다.
기본적으로 REST API 여러개의 URL을 활용하여 작동합니다. 모든 URL 은 각각 고유하고, 각기 다른 데이터를 제공합니다.
하지만, 이러한 REST API 는 2가지 큰 문제점을 가지고 있습니다.
Problems
1. Over Fetching
클라이언트가 필요한 것보다 더 많은 데이터를 가져오게 되는 경우를 Over Fetching 이라고 볼 수 있습니다. 예를 들어, 영화 목록에서 제목만 필요하지만, 영화 목록을 가져오는 API 는 제목, 내용, 사진 url 등 더 많은 정보를 돌려주게 구현되어있는 경우가 있을 수 있죠. 만약 조금이라도 다른 응답의 데이터를 가지고 오고 싶다면, 새로운 엔드포인트 API 구현이 필요해집니다.
query parameter 를 활용하면 되지 않을까? 하는 의문이 들 수 있습니다. 저도 그랬고요. /list?field=title 과 같은 식으로 요청하면 title 만 돌려주게 구현할 수 있을 것입니다. 다만, 이는 표준화된 방식이 아니죠. 그리고 더 복잡한 데이터 요청은 query parameter 만으로 요청하는 것이 오히려 어려울 수 있습니다.
GraphQL 은 이러한 문제를 해결해줍니다. GraphQL 의 QL 이 Query Language 인 것 답게, 이는 클라이언트가 정확하게 필요한 데이터만 요청할 수 있게 해줍니다.
2. Under Fetching
Under Fetching 은 Over Fetching 과 반대되는 말로, 필요한 만큼의 데이터를 한번에 가져오지 못한다는 문제점을 의미합니다. 예를들어, 클라이언트에서 게시글을 클릭했을 때 포함되어야 하는 정보는 다양하게 존재합니다. 게시글 그 자체에 대한 데이터, 게시글 작성자에 대한 데이터, 게시글 댓글에 대한 데이터가 포함될 수 있죠. 만약 이를 각각의 엔드포인트로 구성하였다면, 클라이언트에서는 다음과 같이 3가지 GET 요청을 보내야할 것입니다.
/posts/{id} to get the post.
/authors/{id} to get the author of the post.
/posts/{id}/comments to get the comments on the post.GraphQL 에선 이를 간단하게 한번의 요청만으로 해결해 줍니다.
query {
post(id: "1") {
title
content
author {
name
bio
}
comments {
content
date
}
}
}REST API 에서도 물론 한번의 요청으로 이를 해결할 수는 있습니다. /post/{id}/detail 과 같은 API 를 추가로 구현하면 되겠죠.
하지만, 서비스가 커지며 데이터 모델이 점점 변경되고, 비슷하지만 다른 응답이 요구되는 다양한 상황이 추가될 수 있습니다. 이 때마다 새로운 API 를 작성하는 것은 매우 비효율 적일 것입니다. 데이터 모델은 변화가 없지만, 단순히 다른 형태의 응답이 요구되는 경우에도 클라이언트와 서버 작업이 모두 이루어 져야 할 것입니다.
그에 비해 GraphQL 을 활용할 경우에는, 데이터 모델에 변화가 없는 상황에선, 클라이언트 개발자가 단순히 필요한 정보의 새 쿼리를 만들면 끝입니다.
물론 GraphQL 을 잘 활용하기 위해선, 서버 개발자가 보다 정확한 타입의 스키마를 정의하고, 중첩된 쿼리를 해결하고, 쿼리 최적화와 같은 작업을 처리해야 하기 때문에 REST API 에 비하여 사전 작업이 더 필요할 수는 있습니다. 하지만 사전 작업이 모두 완료되면, GraphQL은 클라이언트에게 매우 유연하고 효율적인 API를 제공할 수 있습니다.
GraphQL 은 어떻게 동작하나요?
실질적으로 GraphQL 의 구현은 REST 와 마찬가지로 HTTP 요청과 응답을 활용하며, 데이터는 json 포맷으로 이루어져 있습니다. 메서드는 일반적으로 POST 가 사용됩니다. GraphQL 쿼리 자체가 body 에 포함되기 때문이겠죠.
응답 코드는 서버 자체 에러나, GraphQL 을 파싱할 수 없는 경우 등 특별한 상황을 제외하면, 항상 200 이 리턴됩니다. 응답 데이터에서 에러 여부, 에러 메세지를 돌려보내는 것이죠.
GrpahQL 의 결함은 무엇이 있을까요?
비교적 무거운 툴과 함께 사용해야 합니다.
REST 의 경우 특별한 라이브러리 없이도 다른 누군가의 API 를 호출할 수 있습니다. 단순히 curl 을 통해서도 가능하죠. 이에 비하여 GraphQL 은 클라이언트, 서버 모두 꽤 무거운 툴이 필요합니다. 이는 꽤 큰 금액의 비용을 발생시킬 수 있죠. 만약 단순히 CRUD 를 활용하는 서비스를 개발하는 것이라면, 이는 금액적으로 많이 비효율적일 것입니다.
캐싱 기능이 비교적 떨어집니다.
REST 는 GET 메서드를 자주 활용하며 데이터를 요청하는데, 이 GET 메서드는 잘 정의된 캐싱 기능들이 존재합니다. 다양한 브라우저, CDNs, 프락시, 웹서버에서 이를 활용하죠. 그에 비해 GraphQL 은 기본적으로 POST 메소드를 활용합니다. 이는 HTTP caching 을 최대로 활용할 수 없게 만들죠.
잘만 다룬다면, GraphQL 도 HTTP caching 을 잘 활용할 수 있습니다. 다만, 상세한 내용은 복잡하기 때문에, 결국 HTTP 캐싱을 잘 활용하기 위해선 추가적인 작업이 필요하고, 그 작업이 사소하진 않을 것이라는 점을 이해하고 넘어가는게 좋을 것 같습니다.
클라이언트가 원하는 데이터를 요청할 수 있다는 점이 단점이 될 수 있습니다.
클라이언트에 새로운 기능이 추가되며, 서버에서 예상치 못한 데이터를 요청하는 경우가 생길 수 있습니다. 이러한 요청이 크리티컬한 테이블 스캔을 발생시킬 수 있고, 이는 데이터베이스 다운으로 이어질 수 있습니다.
완화하는 방법은 있지만, 이는 GrpahQL 구현에 복잡성을 증가시킵니다.
위 3가지 결함에 대한 보호 조치 비용은 GraphQL 사용 여부를 선택하는데 중요하게 고려해야할 요소입니다.
GraphQL 의 특징
GraphQL 단순하게 표현하면 API Layer 에서 사용 가능한 Query Language 라고 할 수 있으며, 크게 3가지 특징을 추려보면:
- 필요한 것만 요청하고 받아오기
- 단일 요청으로 많은 데이터를 가져오기
- 가능한 케이스를 타입 시스템으로 표현하기
정도가 존재합니다. 여기서 1, 2번은 쉽게 이해할 수 있습니다. 결국 둘 다 payload 를 최적화 하는 것이 목적인 것이죠. 하지만, GraphQL의 진정한 강점은 3번, 클라이언트 사이드에서 타입 시스템을 구축할 수 있다는 점인 것 같습니다.
아무래도, 실제 서비스에서 어떻게 사용되는지 볼 수 있으면 가장 좋겠죠. NAVER DEVIEW 2023에서 권기범, 오제관님께서 발표한 "GrpahQL 잘 쓰고 계신가요?" 를 꼭 한번 보시길 추천 드립니다. 저는 그 중 중요하다고 생각하는 몇가지 요소를 간단하게 요약해 보겠습니다.
타입 시스템
네이버의 MY플레이스 서비스는 여러 화면에서 내부 DB 는 물론, 다양한 다른 팀에 API 를 사용한다고 합니다. 이를 각각의 컴포넌트에서 직접 연결하여 사용할 수 있겠지만, 클라이언트 개발자 입장에서는 상당히 번거롭고, 신경쓸게 많아질 수 있겠죠. 이 때문에 MY플레이스 서비스 팀에선 중간단계에 GraphQL BFF 를 두었습니다.
여기서 BFF 란 Back-End For Front-End 의 약자로, 클라이언트 개발자를 위한 일종의 게이트웨이라고 볼 수 있습니다. 이는 여러 자원의 출처를 하나의 타입시스템으로 관리할 수 있게 해줍니다. 이를 통해 클라이언트는 오직 한가지 엔드포인트만 활용하며 GrpahQL 을 통해 원하는 데이터를 주고 받을 수 있는 것이죠.
즉, 출처가 다른 데이터들의 통합 타입 시스템 이 구축됩니다. 이제 클라이언트 개발자는 여러 내부/외부 API 를 신경쓸 필요 없이, BFF 에서 제공되는 타입들을 활용화며, 화면 중심으로 스키마를 작성해 나갈 수 있습니다. 이를 통해 클라이언트 개발자의 DX 가 상당히 좋아집니다.
Normalization
다음으로 한가지, 일반적인 REST API fetch 라이브러리에서는 활용이 불가능한 중요한 기능이 GraphQL 구현 라이브러리에는 존재합니다. 그것은 바로 Normalization 이죠.
이게 무엇인지 알아보기 전에, 기존에 REST API 를 사용할 때의 상태 변화에 따른 UI 업데이트 문제를 살펴보겠습니다.
유저가 하단 피드에 팔로잉 버튼을 클릭하였을 때, 크게 2가지 상태가 업데이트 되어야 합니다. 팔로우 버튼이 팔로잉으로 변해야 하고, 상단 프로필에 팔로잉 숫자 또한 업데이트 되어야 합니다. (물론, 실제 서버 구현에 따라 팔로잉 수가 바로 변하지 않을 수는 있지만, 이 발표에서는 유저가 팔로잉시 팔로우 수도 바로 변한다고 가정한 것 같습니다)
기존에 클라이언트 개발자라면 이를 어떤식으로 구현할까요? 먼저, 상태 관리 프레임워크를 통해 이를 직접 관리하는 방법입니다.
집중력 총동원이 필요하겠죠. 구조가 복잡해질수록 이를 직접 찾아서 등록하는 것이 번거로울 것입니다.
두번째 방법은, 무지성 refetch 가 있을 것 같네요.
서버 개발자의 원성을 살 수 있을 것 같아요. 사실 단순히 원성의 문제가 아니라, 리소스 비용을 증가시키는 것이기 때문에 더욱 주의해야할 것 같습니다.
이러한 상황에서 GraphQL 의 Normalization 이 빛을 발합니다. GraphQL 은 일반적인 Rest API 방식과 다르게, 서버로 부터 응답받을 모든 데이터 스키마 타입을 미리 알고 있기 때문에, 1. 서로 다른 컴포넌트에서 같은 상태를 참조할 수 있고, 2. 중복된 데이터가 존재하지 않도록 Normalization 이 가능해 집니다.
먼저, 우측의 json 형식의 data 는 일반적인 GraphQL 요청에 따른 데이터 응답입니다. 클라이언트가 화면을 업데이트 하는데 필요한 follwingCount, followState 값이 들어있죠.
좌측은 Normalized Cache 로, GraphQL 라이브러리를 통해 관리됩니다. 응답이 도착하면, GrpahQL 라이브러리는 Normalize Process 에 따라 필요한 필드에 값을 업데이트 합니다.
이게 끝입니다.
클라이언트에서는 화면 UI 업데이트를 위해 Global State Manager 를 사용할 필요도, Refetch 할 필요도 없어집니다.
마찬가지로, 클라이언트 개발자의 DX 가 상당히 좋아지겠죠?
Fragment
다음으로, GraphQL 의 특징 중 하나인 Fragment 에 대하여 이야기해 보겠습니다. 이를 잘 이해하려면, 기존에 어떤 문제가 존재하는지 살펴보는게 빠르겠죠.
문제가 보이시나요?
문제는 쿼리를 보내는 곳과 쓰는 곳 사이의 거리가 멀다는 것이죠. 최상위 컴포넌트에서 쿼리를 보내고, 값이 필요한 컴포넌트까지 이를 내려주어야 하는데, 거리가 점점 멀어집니다.
하위 컴포넌트에 새로운 데이터 의존성이 생긴다면, 상위 컴포넌트까지 직접 따라가서 이를 추가해 주어야겠죠. Component tree 가 더 복잡하고 호출처가 다양해진다면, 이와 관련한 데이터 의존성의 변경이 필요한 경우 많이 번거로워 질 것입니다.
두번째 문제는, 최상위 Query 에서 필드별 사용 유무 판단이 어렵다는 점입니다. 응답으로 받은 데이터 하나를 하위 컴포넌트에서 사용하는지 여부를 알고 싶다면, 모든 컴포넌트를 뒤져봐야겠죠. 결국 이는 변경을 어렵게 만듭니다.
만약, Component 가 자신이 필요한 데이터 의존성을 선언만 하고, Bottom-Up 방식으로 최상위 Query 에게 전달된다면 이 문제가 해결될 수 있지 않을까요?
이를 가능하게 해주는 것이 바로 Fragment 입니다.
각 컴포넌트는 본인이 필요한 데이터를 Fragment 로 작성합니다. 이는 최상위 Query 로 전달되어 한번에 요청으로 전달되고, 각각의 필요한 응답은 각 Fragment 를 선언한 컴포넌트에게 저절로 떨어지게 되죠.
만약 새로운 데이터 의존성이 생긴다면?
다음과 같이 간단하게 해결됩니다.
다시한번, 클라이언트 개발자의 DX 가 증가하겠죠? ㅎ
발표는 DX 의 증가는 UX 의 증가로 이루어 질 것이라고 말씀해 주시면서 마무리 됩니다. (공감합니다)
이 외에도 여러가지 중요한 핵심 특징이 많으니 궁금하신 분들은 하단 참고에 url 을 따라 DEVIEW 를 직접 시청하시는 것을 권장드립니다.
정리
사실 GraphQL 을 제대로 공부해보기 전까지는, GraphQL 이 만능인 줄로 알고 있었습니다. 하지만, 분명히 문제점도 존재하고 trade-off 이기 때문에 이를 비지니스 레벨에서 활용하려면 많은 고민이 필요하겠죠.
다만, 클라이언트 어플리케이션을 직접 구현해 본 입장에서, GraphQL 이 가져다 주는 변화는 정말로 좋은 DX 를 보장해 줄 것이라는 점은 확실한 것 같습니다.
새로운 것을 시도하는 것은 좋은 개발자로 발전하기 위한 소양이라고 생각합니다. 다음에 클라이언트 어플리케이션을 개발할 기회가 있다면, 꼭 한번 GraphQL 을 사용해 보고 싶다는 생각이 드는 것 같습니다.
참고
https://www.youtube.com/watch?v=N-81mS2vldI
https://www.youtube.com/watch?v=9G2vT4C4sAY
https://www.youtube.com/watch?v=yWzKJPw_VzM
- ChatGPT-4